补:最近看了一个AI的学习视频与关于贝叶斯分类,SVM的文章,发现一个问题,就是都是解释已经总结的知识,而没有从直觉上给出产生这样处理的思路。这样的知识,对我来说,没有形成整体脉络,演进思考。
什么是AI,它实现的是什么?实现路径是怎样的?我自己这么总结:
- 1. 人们已经知道AI可以识别文字,照片。实现上就是建立了一个x到y之间的函数f(x),当你输入一个手写一个字时,给出一个标准的字。那么这个函数是什么样子的呢?AI中有监督学习就是解决这个问题。
- 2. 这个f(x)很难用一个数字表达式写出来,不过可以找一些可模拟任意f(x)的计算结构体来模拟这样的计算,因为有监督,所以可以计算出来的值与真实值比较来调整参数,完善这个计算结构体。
- 3. 那么到底有什么计算结构体可以用?假如最简单的一个手写体与标准字大小差不多,那通过判断像素的重叠度就可以找出最像的字。那对于缩放、旋转、色彩等发生变化了怎么办?也许就想到了多层的点阵结构,于是有了神经网络的层层运算。而分类的情况下,从一个树就演化成多树或者提升树。像素的对比或者分类演化出计算结构,也许以后有其它计算模型也是按应用的领域,从一个简单的结构开始的。
- 4. 大概的结构有了,那调整参数就是权重,而减少线性因素就有了激活函数。而这个结构算出来的值与真实值的差就是损失,如何减少损失,就要反馈调整或者新建个提升树调整,而调整多少呢?就如同你射箭调整,玩冰壶调整,一点点减少与目标的差别。如果收敛就调整好了。因为计算结构很复杂,就会把不靠谱的修正也放进去了,反正效果不好,这样就有了正则项,复杂了不好,与损失函数合在一个公式中,让损失小时,尽量也简单,也许就有了一个最优的点。
- 5. 接下来说说这个xgboost,它是属于分类的大概念,一个树一个树的产生,让树叶子值的和慢慢靠近标准答案。优化函数好就比较快收敛,因为有极值问题所以要考虑到一个导数。这个xgboost的定位就是用二阶导数产生提升树。
1. 介绍
以前看过一点点CNN图像识别原理,这两天看一下基于树的XGBOOST。先了解其原理,加上自己不成熟的直觉理解,还有几个疑问。最后用一个例子,使用python试用一下,仅作为学习笔记。不系统整理下来,就会看了又看,忘了又看。
我觉得直觉理解的好处是更容易记忆,更容易触类旁通,也容易归纳与推广。有时候解决问题就是直觉+验证的过程
陈天奇在Quora上的解答如下:https://www.codercto.com/a/5669.html
不同的机器学习模型适用于不同类型的任务。**深度神经网络**通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据。而**基于树模型的XGBoost**则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。
这两类模型都很重要,并广泛用于数据科学竞赛和工业界。
- XGBoost专注于模型的可解释性,而基于人工神经网络的深度学习,则更关注模型的准确度。
- XGBoost更适用于变量数较少的表格数据,而深度学习则更适用于图像或其他拥有海量变量的数据。
2. 原理+直觉描述
通过样本每次进行树分类后的值,计算损失函数,产生一个新的树,让损失超来越少,最后结果越接近(当然还有正则去惩罚复杂度,防止过捏合)。树是不断提升的过程,每增加树的结果之和,与结果越近。
实战的流程一般是先将数据预处理,成为我们模型可处理的数据,包括丢失值处理,数据拆解,类型转换等等。然后将其导入模型运行,最后根据结果正确率调整参数,反复调参数达到最优。
2.1 公式推导
https://blog.csdn.net/sxf1061926959/article/details/78303555

> 上图上:L是损失函数,有两个参数,一个是样本的结果,一个是前一次预测值加本次预测值。后面是正则。总体上要求所有样本的损失和最小。
>
> f(x)算是新树对一组数据的映射,经过分类得到的一个值,是一个叶子节点的值。f(x)可以认为是树的特点,树的关键特点就是是结构与叶子值两个变量。树的复杂性,就是特点的函数。
> 上图下:由于目标是可以逐步接近的一个函数,而且是按每 + 一个树,进行接近。所以前一个树得到的值是知道的,要推断后面的值,从历史去预测未来,这种递推可以用泰勒公式。自变量的差值就是增加了这个树。
>
> 前一个的叶子与目标的差距,用来确定这一次的叶子值,但无法用前一次的结构(划分)与目标的差距,确定这一次的结构。那么结构这个问题暂缓。

> 上图上:有了上次预测值,及差距,还有损失函数---L (已经知道了,或者先设置好了),二阶导数就有了。
>
> 上图下:目标就是,上次的绝对函数损失值与损失的梯度对新树特征变化的影响。就是找到下次怎么构建树。树的特征要随着损失的两阶梯度变化,让目标趋向缓和,接近,收敛...
>
> 树的特征先抛去结构(划分),主要就是这个叶子值。本次叶子值与之前叶子值的一阶导数+本次叶子值^2与之前二阶导数积,共同影响目标的变化趋势。
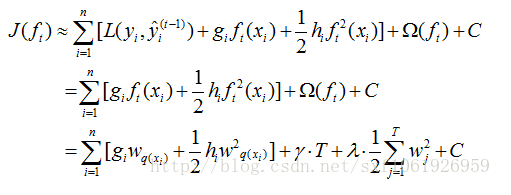
> 上图:q就是第一组数据的导数,h是二阶。f(x)值就是抛弃结构后就是这组所在的叶子值。上次的损失是常量了,只看损失的两阶趋势。
>
> 叶子个数,与叶子值两个构成了惩罚函数,叶子太多,值太离散就不好了。所以这个也要有变小的趋势要求。

> 上图:原来是按样本数汇总,可以按叶子分组后,就变个样子。这样把公式的惩罚部分与损失部分可以按叶子进行组合。一个样本对叶子值的变化趋势要求,变成落在这个叶子上的样本对这个叶子值的趋势要求小汇总。
>
> 现在大概总结一下这个函数中的自变量:
>
> 叶子的个数,叶子节点的值是,当然树的的结构也是。之前把f(x)变成w是一种简化。等适当的时候,再把w回归为对结构的考虑。上面公式中的3个变量中,叶子的个数与划分都先不考虑(也没办法考虑,或者说叶子数有限的,划分也是有限的,相对于样本数的量来说,影响会小)。
> 这时候仅仅看看叶子值对目标的偏导影响要趋0,得到下面的最佳叶子值。也就是从之前一个树的叶子值对样本目标函数的趋势,来推断出本次的叶子值。
>
> 其实如果与前一次的结构保持一致的话,就是单一变量,纯的叶子值的了。结构是很难讲的东西,如果每次结构不同,那每次同一个叶子上的样本组合也是变化的东西。

> 现在新叶子值随历史叶子值的趋势得到的新值有了,叶子值与目标的关系早有了,所以历史叶子值趋势与目标的关系也有了。
> 如果只用一阶导数,目标对叶子值的偏导数是Gj,无法找到最优叶子值。
>
> 综上,新的树的影响来源于叶子值与结构两个变量。叶子值要让目标函数趋势变小,好的结构也要让目标函数变小。
2.2 树的结构
> 在生成结构的时候,就要考虑划分后,样本的历史叶子值趋势对目标函数值的变化是怎么的。那么可以试着多种划分,看看哪个划分出来的目标函数值最小,当然也可能不划分比较好。
>
> 划分当然会造成模型复杂,所以有要代价的。

> 划分略
3. 总结、感悟与疑问
3.1 总结
XGBoost是在构建一个个树,值累加,让目标(主要是损失)变的最小。
已经构建了t-1个树,新的树要根据历史树趋势进行优化构建。历史树上能拿到的趋势只是历史叶子节点值,拿不到结构的历史趋势,那就只能以历史叶子值,去找新叶子值。
目标函数的3个变量中(树结构,叶子个数与叶子值),叶子值是唯一有趋势变化的东西,而且与样本结果值密切相关。结构每次也变化,但无法从历史推出当前,叶子数忽略。
通过通用公式以及配合树这种结构的特点,找到叶子与目标的偏导数关系,找出最优的叶子值。叶子值与树结构是没有关系的,所以保持叶子值最优的情况下,找到对目标函数值最好的结构,按这个划分产生结构。
3.2 感悟
> 总的来说,建模过程中,目标就是结果损失要小(头),模型复杂度小(尾);
>
> 损失方面,可能有多个变量影响,有可以计算损失确定的值变化,也有不可琢磨的变化。
>
> 根据采用的结构的特色,把损失与正则中的变量合并起来,如果同一个变量不能把损失与正则进行统一,那多个变量更是无从下手。作者通过同一个叶子的汇总,越是巧妙,越可能有好的成果。
>
> 目标=(变量1头+变量1尾)+(变量2头+变量2尾)+(变量3头+变量3尾)--》 目标=(变量1)+(变量2)+(变量3)
>
> 变量之间无关,根据具体每个变量特点,变量的变化情况,与结果的关联,及趋势值特点是什么,导数求变量最优值,或者根据结果值反推另外变量的最优。
3.3 疑问
1. 如果尽量按样本项目构建一个比较复杂的树,每次只调整叶子值,会有什么效果?或者在划分点增加一个变量是怎么的?这有点像网络了。
2. 如何损失函数只考虑一阶,效果是怎么的?找不出自变量叶子值的最优值。三阶呢?估计计算太多了。
3. 很想知道作者最初是怎么有灵光一现,搞出xgboost的?
4. 例子
找到一个有数据的例子,源码在:https://blog.csdn.net/m_buddy/article/details/79341058
```python
print (predict_res)//修改加了括号
```
4.1 两个库的安装
```python
import matplotlib.pyplot as plt
import xgboost as xgb
```
https://blog.csdn.net/ifreewolf_csdn/article/details/82988179
安装解决方法:没有在pycharm中安装,因为超时失败,找到E:\pythonproj36\pythonproj\Scripts下的pip.exe,在cmd下安装的。
Microsoft Windows [版本 10.0.17134.1130]
(c) 2018 Microsoft Corporation。保留所有权利。
C:\Users\ACER>E:\pythonproj36\pythonproj\Scripts\pip.exe install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting matplotlib
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/44/fb/132de6a4b803d8ce909a89043b7d3f775f64e0a39398fc98c02e3e144b61/matplotlib-3.1.2-cp36-cp36m-win_amd64.whl
。。。。。
Installing collected packages: kiwisolver, cycler, python-dateutil, pyparsing, matplotlib
Successfully installed cycler-0.10.0 kiwisolver-1.1.0 matplotlib-3.1.2 pyparsing-2.4.5 python-dateutil-2.8.1
C:\Users\ACER>E:\pythonproj36\pythonproj\Scripts\pip.exe list
Package Version
------
。。。
lxml 4.3.3
Markdown 3.1
matplotlib 3.1.2---------------------------
。。。
Werkzeug 0.15.4
wheel 0.33.4
xgboost 0.90--------------------
C:\Users\ACER>
```
(1)加时间
pip install -U --timeout 1000 matplotlib
(2)换成清华的镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
4.2 可视化
```
#自己在这基础上加了这么几句,输出三棵树
plot_tree(bst,num_trees=0)
plt.show()
plot_tree(bst, num_trees=1)
plt.show()
plot_tree(bst, num_trees=2)
plt.show()
```
要运行,要先下载graphviz,配置环境变量,重启PyCharm,或者import os
pip也要安装:pip install pydot 与 pip install graphviz。
4.3 运行结果




 4.4 调参简介
4.4 调参简介
```
xgboost 有很多可调参数,具有极大的自定义灵活性。比如说:
(1)objective [ default=reg:linear ] 定义学习任务及相应的学习目标,可选的目标函数如下:
“reg:linear” –线性回归。
“reg:logistic” –逻辑回归。
“binary:logistic” –二分类的逻辑回归问题,输出为概率。
“multi:softmax” –处理多分类问题,同时需要设置参数num_class(类别个数)
(2)’eval_metric’ The choices are listed below,评估指标:
“rmse”: root mean square error
“logloss”: negative log-likelihood
(3)max_depth [default=6] 数的最大深度。缺省值为6 ,取值范围为:[1,∞]
```
分享到:





相关推荐
adboost、gbdt、xgboost学习笔记
Java学习笔记+程序员生涯。值得一看。
HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记 HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记 HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记HTML+CSS学习笔记 ...
前端的学习笔记HTML+css前端的学习笔记HTML+css前端的学习笔记HTML+css 前端的学习笔记HTML+css前端的学习笔记HTML+css前端的学习笔记HTML+css 前端的学习笔记HTML+css前端的学习笔记HTML+css前端的学习笔记HTML+css...
html+css+js学习笔记html+css+js学习笔记html+css+js学习笔记html+css+js学习笔记 html+css+js学习笔记html+css+js学习笔记html+css+js学习笔记html+css+js学习笔记 html+css+js学习笔记html+css+js学习笔记...
深度学习 深度学习笔记+试题练习+答案解析 深度学习笔记+试题练习+答案解析 深度学习笔记+试题练习+答案解析 深度学习笔记+试题练习+答案解析 深度学习笔记+试题练习+答案解析 深度学习笔记+试题练习+答案解析
html+css前端学习笔记html+css前端学习笔记html+css前端学习笔记 html+css前端学习笔记html+css前端学习笔记html+css前端学习笔记 html+css前端学习笔记html+css前端学习笔记html+css前端学习笔记 html+css前端学习...
HTML+CSS+JavaScript教程学习笔记HTML+CSS+JavaScript教程学习笔记 HTML+CSS+JavaScript教程学习笔记HTML+CSS+JavaScript教程学习笔记 HTML+CSS+JavaScript教程学习笔记HTML+CSS+JavaScript教程学习笔记 ...
Ext 手册+学习笔记+资料+实例 Ext 手册+学习笔记+资料+实例 Ext 手册+学习笔记+资料+实例
狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神SpringBoot笔记+源码 狂神...
SpringBoot学习笔记+新手练习源码 SpringBoot学习笔记+新手练习源码 SpringBoot学习笔记+新手练习源码
python学习笔记+源码练习,简单易懂,让你从入门到不放弃
Java IO学习笔记+代码,全面介绍IO中的方法、类,很适合初学者
JAVA-WEB学习笔记+JSP学习笔记
mysql学习笔记+基础部分+附带图片
Java学习笔记+程序员生涯 软件工程师必备
Linux内核与设备驱动程序学习资料笔记+源码.zipLinux内核与设备驱动程序学习资料笔记+源码.zipLinux内核与设备驱动程序学习资料笔记+源码.zipLinux内核与设备驱动程序学习资料笔记+源码.zipLinux内核与设备驱动程序...
jsp2.0 学习笔记+完整源码,包含了JSP开发中要用到的知识.
混合A星学习笔记+记录
QTP关键教程+学习笔记+VB脚本语言学习